
1. September 2022, 9.00 Uhr
Intelligentes Input Management als Erfolgsfaktor:
Unstrukturierte oder teilstrukturierte Daten stellen große Hürden für rein digitale Prozesse bei Versicherungen dar
Obwohl seit vielen Jahren das Ende des Papiers prognostiziert wird, geht die Unternehmensberatung McKinsey trotz zunehmender Digitalisierungsinitiativen davon aus, dass die papierbasierte Dokumentenverarbeitung noch viele Jahre andauern wird.
Es wird nicht möglich sein, kurz oder mittelfristig papierbasierte Dokumente komplett abzuschaffen. Gründe dafür sind strenge Datenschutzrichtlinien, etablierte Prozesse, hohe Wechselkosten und die Schwierigkeiten, die Kunden dafür zu motivieren, bei selten wiederkehrenden Ereignissen eine App zu verwenden. Deshalb müssen jetzt bessere Wege gefunden werden, mit unstrukturierten Daten effizient umzugehen – solange, bis die Vision von zu 100 Prozent digitalen Prozessen umgesetzt werden kann. Akkurate, strukturierte Daten sind die Basis für die erfolgreiche Umsetzung von Digitalisierungsvorhaben.
Das Problem
Input-Management-Lösungen mit über 20 Jahren zurückreichenden Ursprüngen sind darauf ausgelegt, sparsam mit vorhandener Rechenleistung umzugehen. Entsprechend ist die Softwarearchitektur konzipiert. Heutige KI-basierte Hochleistungsmodelle des maschinellen Lernens können hier nur unzureichend, bis gar nicht eingebunden werden. Die etablierten Anwendungen sind profitabel und scheuen die Einführung disruptiver Neuerungen und Durchführungen entsprechender Upgrades bei Bestandskunden. Falls keine signifikanten Produktentwicklungen erfolgen, werden diese bald von intelligenten Dokumentenverarbeitungssystemen (iDv) abgelöst. Neue Anbieter drängen auf den Markt und machen auf Basis technologischer Disruption und wettbewerbsfähigerer Preismodelle den etablierten Lösungen das Leben schwer.
Technologische Evolution – Die Bedeutung von iDv
Lösungen, um unstrukturierte Daten in strukturierte zu transformieren, sind nicht neu. Allerdings sind diese erst in jüngster Zeit tatsächlich „intelligent“ geworden. Wenn in diesem Beitrag die Rede von iDv ist, so meint dies die Kombination aus einer Vielzahl hochmoderner Technologien, welche weit über den monolithischen Einsatz von OCR, Machine Learning und RPA hinaus geht. iDv beschreibt vielmehr einen kombinierten, ineinander verzahnten Ansatz bestehend aus Bildbearbeitungstechnologien, kombinierten ICR Engines, Computer Vision, NLP und KI.
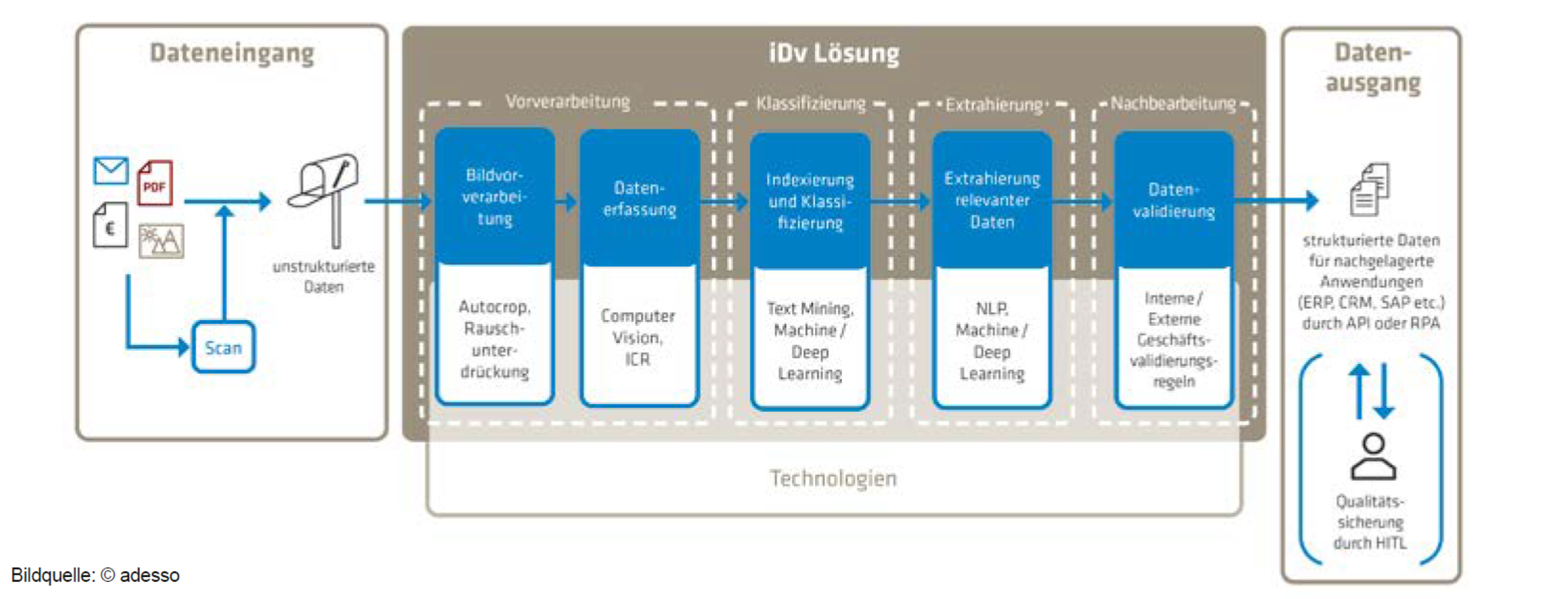
Eine zielführende Kombination von vorhandenen Technologien in der intelligenten Dokumentenverarbeitung
Datenhunger, Rechenleistung und Cloud
Moderne Machine-Learning-Modelle benötigen hohe Rechenleistungen. Hyperscaler bieten die erforderliche Rechenpower, um den Datenhunger zu stillen – denn das Ausführen paralleler Rechenoperationen ist teuer und nach Etablierung im eigenen Rechenzentrum schnell technologisch überholt. Die Cloudfähigkeit von iDv-Lösungen ermöglicht es zum einen, Lastspitzen durch hohe Skalierbarkeit komfortabel abzufedern und andererseits bei saisonalen Schwankungen nach unten Rechenleistung nicht zu verschenken. Reine Extraktionslösungen der Hyperscaler selbst sind nicht als ernsthafte Alternative zu einer vollumfänglichen iDv-Lösung zu betrachten, da Versicherungen vielmehr eine holistische Lösung zur Dokumentenverarbeitung fordern.
Der Mensch bleibt im Zentrum
Bei aller Technologie bleibt der Mensch im Zentrum des Geschehens. Variierende Dokumentenformate, verzerrte Dokumente, die Interpretation natürlicher Sprache und limitierte Datenmengen in spezifischen Fallkonstellationen setzen den genannten Technologien nach wie vor Grenzen. Der Mensch ist integraler Bestandteil des Prozesses und behält eine wichtige Funktion im Gesamtprozess:
- Vortrainieren der ML Modelle,
- Konfigurieren und Trainieren der Lösung,
- Fortlaufendendes d. h. kontinuierliches Training und Lernen der KI im operativen Betrieb.
Hohe Automatisierung ist das Ziel
Die Bestandteile einer iDv-Lösung sind komplex und übernehmen Aufgaben wie das Lesen, Erkennen, Interpretieren und Analysieren von vorhandenen Informationen. Fehlt es einer iDv an Intelligenz, geht dies zu Lasten der angestrebten hohen Dunkelverarbeitungsquote. Versicherungen, die sich einen nachhaltigen Wettbewerbsvorteil erarbeiten möchten, betrachten die iDv als End-to-End-Prozess mit drei Phasen:
- Inbound: Dokumenten-Erfassung
- Workflow: Interne Verarbeitung in zielgerichteten und automatisierten Workflows
- Outbound: Effiziente Bereitstellung der strukturierten Daten an Dritte
Der Teilbereich Inbound ist besonders wichtig und beinhaltet folgende Schritte:
- Bereitstellung einer Scan-Lösung, welche in optimaler Qualität die vorhandenen Dokumente in Bilder wandelt.
- Bildbearbeitung, mit deren Hilfe sich Dokumente aufbereiten lassen. Es werden hier schlechte Input-Qualitäten bestmöglich verbessert, um mit niedrigen Auflösungen, ungewöhnlichen Farben und Dokumentengrößen, Post-its und gerissen Seiten umzugehen.
- ICR-Modul, welches es ermöglicht, je nach Bedarf automatisiert verschiedene ICR Engines ggfls. mehrschichtig zu verwenden, um die Ergebnisse verschiedener Lösungen miteinander zu kombinieren (Erkennung computer- und handgeschriebener Schrift).
- Die Datenextraktion erfolgt nach entsprechender Anliegenerkennung auf KI-Basis und muss mit State-of-the-Art-Technologie aufwarten, um menschliches Zurechtweisen – Human in the Loop (HITL) – der KI auf ein Minimum zu reduzieren.
- Interpretation der Daten, um diese den jeweils relevanten IT-Systemen bereitzustellen.
- Nutzung der Daten ist einer der entscheidenden Schritte. Nur wenn extrahierte, digital bereitgestellte Strukturdaten in Folgesystemen kanalisiert und dort korrekt konsumiert werden, wird das Projekt der iDv seinen vollen Nutzen entfalten.
Make or Buy?
Eine 100-prozentige Weiterverarbeitung der Strukturdaten in nachgelagerten Systemen ist nicht realistisch, da erfahrungsgemäß 20 Prozent der Vorgänge im zielgerichteten Routing eine Herausforderung darstellen. Es sollten zu Beginn des Projektes messbare Erfolgsindikatoren festgelegt werden, welche entsprechend überwacht werden, um im Bedarfsfall zeitgerecht reagieren zu können. So ist es wichtig, in einer internen Definition festzulegen, was unter maschineller Trefferqualität, HITL und Dunkelverarbeitungsquote zu verstehen ist und bei welchem messbaren Werten die Benchmark für „erfolgreiche Dunkelverarbeitung“ liegt. Anbieter, die Lösungen für iDv kommerziell anbieten, sind meistens technologisch deutlich weiter als solche Lösungen, die Versicherungen mit eigenen Board-Mitteln entwickeln können. Jedes Digitalisierungsprojekt dieser Art erfordert IT-seitig umfangreiches Know-how, Konfigurationen und Entwicklungen. Nur wenn diese eingeplanten Aufwände versicherungsseitig vollumfänglich umgesetzt werden, wird das Projekt der Einführung einer iDv-Lösung zu einem wirtschaftlichen Erfolg.